刚刚,DeepSeek开始频繁更新:Tile Kernels、DeepEP V2
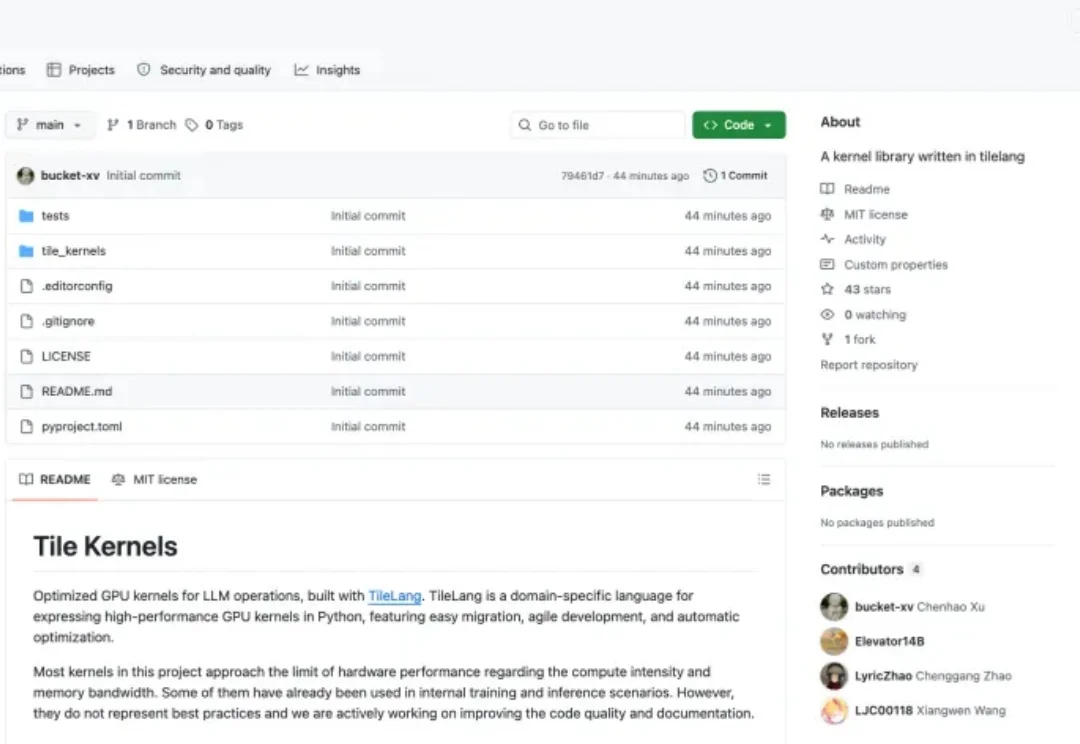
刚刚,DeepSeek开始频繁更新:Tile Kernels、DeepEP V2就在刚刚,DeepSeek 的 GitHub 开始了频繁更新,上线开源了一个新的代码库 Tile Kernels,同时并对 DeepEP 代码库进行了更新,上线了 DeepEP V2。距离上次 DeepSeek 悄悄更新 Mega MoE、FP4 Indexer 还不到一周。
来自主题: AI资讯
9027 点击 2026-04-24 10:09